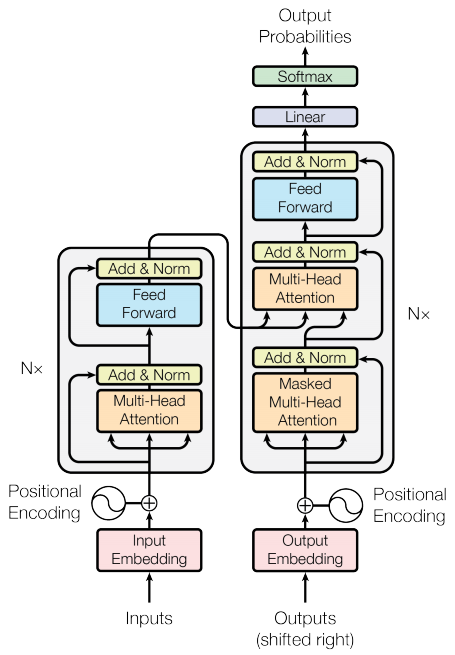
Transformers are deep neural networks that replace CNNs and RNNs with self-attention. Self-attention allows Transformers to easily transmit information across the input sequences.
Neural networks for machine translation typically contain an encoder reading the input sentence and generating a representation of it. A decoder then generates the output sentence word by word while consulting the representation generated by the encoder. The Transformer starts by generating initial representations, or embeddings, for each word… Then, using self-attention, it aggregates information from all of the other words, generating a new representation per word informed by the entire context, represented by the filled balls. This step is then repeated multiple times in parallel for all words, successively generating new representations.
# google colab # Install the most re version of TensorFlow to use the improved # masking support for `tf.keras.layers.MultiHeadAttention`. !apt install --allow-change-held-packages libcudnn8=8.1.0.77-1+cuda11.2 !pip uninstall -y -q tensorflow keras tensorflow-estimator tensorflow-text !pip install protobuf~=3.20.3 !pip install -q tensorflow_datasets !pip install -q -U tensorflow-text tensorflow import logging import time
import numpy as np import matplotlib.pyplot as plt
import tensorflow_datasets as tfds import tensorflow as tf
import tensorflow_text !pip install datasets
Data handling
Download the dataset
Use TensorFlow Datasets to load the Portuguese-English translation datasetTED Talks Open Translation Project. This dataset contains approximately 52,000 training, 1,200 validation and 1,800 test examples.
The following function takes batches of text as input, and converts them to a format suitable for training.
It tokenizes them into ragged batches.
It trims each to be no longer than MAX_TOKENS.
It splits the target (English) tokens into inputs and labels. These are shifted by one step so that at each input location the label is the id of the next token.
It converts the RaggedTensor to padded dense Tensor.
It returns an (inputs, labels) pair.
1 2 3 4 5 6 7 8 9 10 11 12
MAX_TOKENS=128 def prepare_batch(pt, en): pt = tokenizers.pt.tokenize(pt) # Output is ragged. pt = pt[:, :MAX_TOKENS] # Trim to MAX_TOKENS. pt = pt.to_tensor() # Convert to 0-padded dense Tensor
en = tokenizers.en.tokenize(en) en = en[:, :(MAX_TOKENS+1)] en_inputs = en[:, :-1].to_tensor() # Drop the [END] tokens en_labels = en[:, 1:].to_tensor() # Drop the [START] tokens
return (pt, en_inputs), en_labels
The function below converts a dataset of text examples into data of batches for training.
It tokenizes the text, and filters out the sequences that are too long. (The batch/unbatch is included because the tokenizer is much more efficient on large batches).
The cache method ensures that that work is only executed once.
Then shuffle and, dense_to_ragged_batch randomize the order and assemble batches of examples.
Finally prefetch runs the dataset in parallel with the model to ensure that data is available when needed.
# Create training and validation set batches. train_batches = make_batches(train_examples) val_batches = make_batches(val_examples)
Define the components
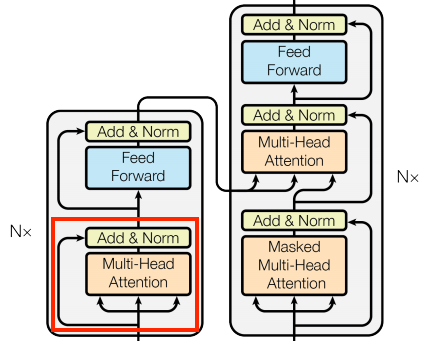
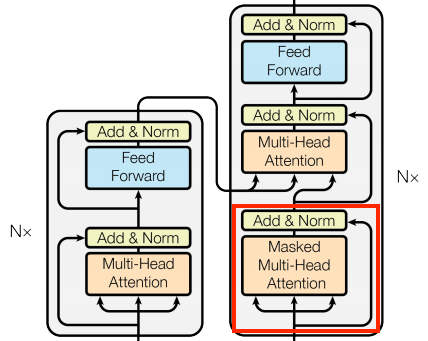
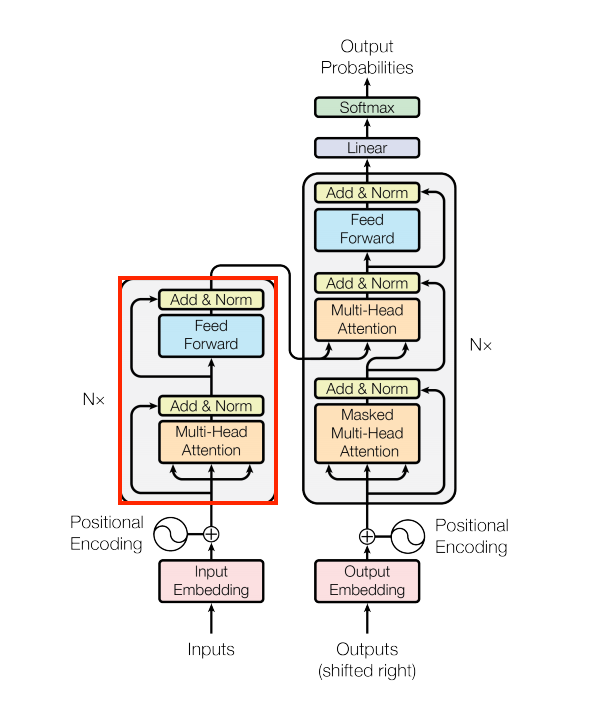
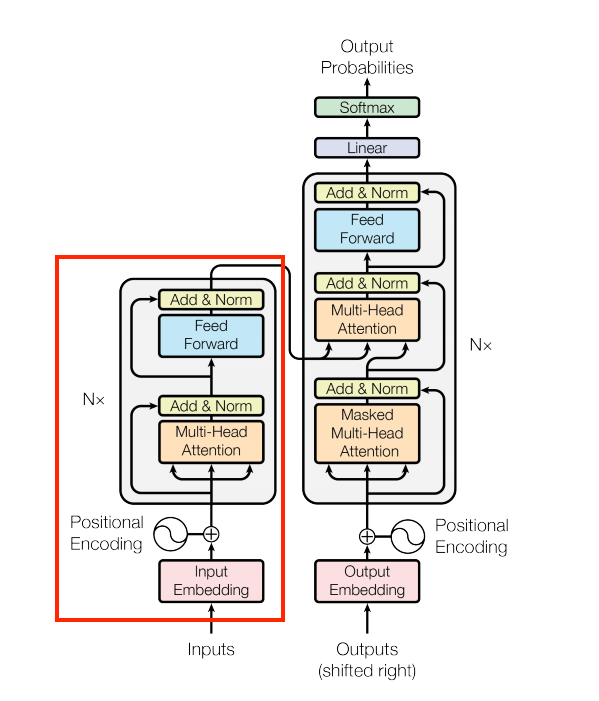
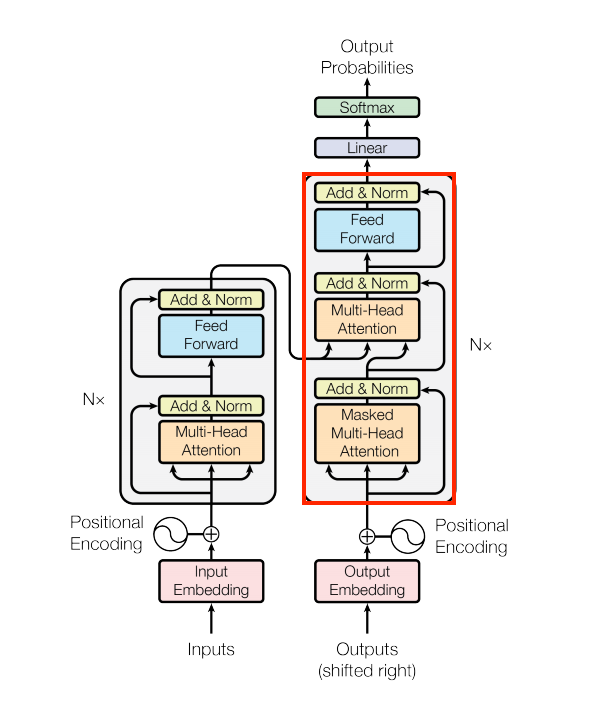
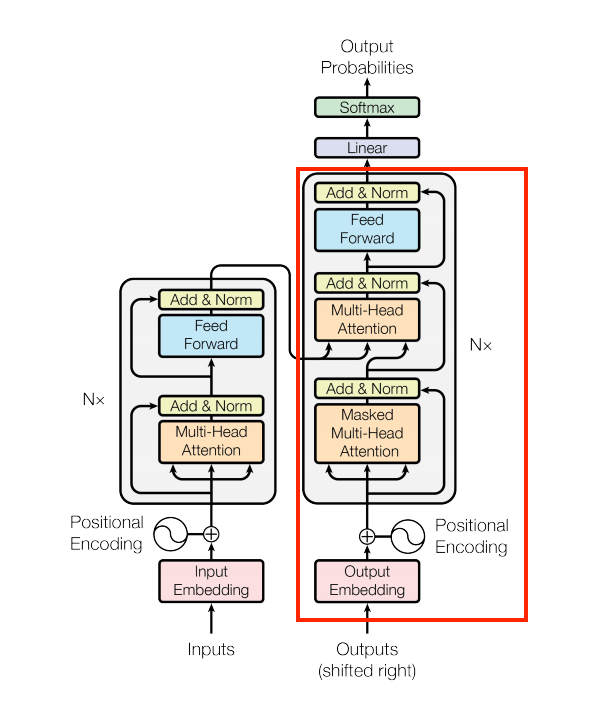
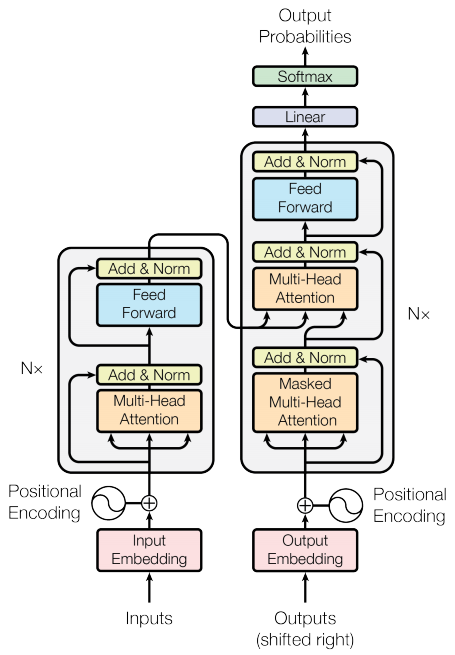
we will start to implement the components of a Transformer as a standard sequence-to-sequence model with an encoder and a decoder.
Figure 1. The original transformer diagram.
The embedding and positional encoding layer
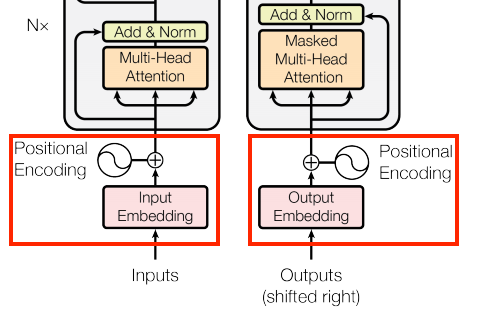
The inputs to both the encoder and decoder use the same embedding and positional encoding logic.
A Transformer adds a “Positional Encoding” to the embedding vectors. It uses a set of sines and cosines at different frequencies (across the sequence). By definition nearby elements will have similar position encodings.
Using the following formula for calculating the positional encoding:
The function using the vectors of sines and cosines concatenated simply to implement it
The position encoding function is a stack of sines and cosines that vibrate at different frequencies depending on their location along the depth of the embedding vector. They vibrate across the position axis.
Creating a PositionEmbedding layer that looks-up a token’s embedding vector and adds the position vector:
def call(self, x): length = tf.shape(x)[1] x = self.embedding(x) # This factor sets the relative scale of the embedding and positonal_encoding. x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32)) x = x + self.pos_encoding[tf.newaxis, :length, :] return x
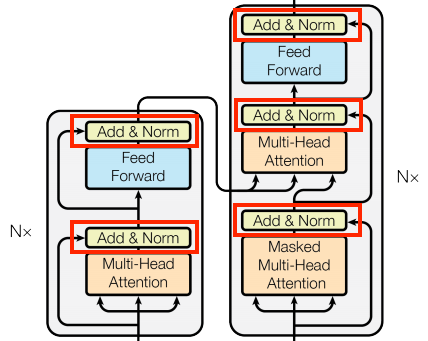
Add and normalise
These “Add & Norm” blocks are scattered throughout the model. Each one joins a residual connection and runs the result through a LayerNormalization layer.
The base attention layer
Attention layers are used throughout the model. These are all identical except for how the attention is configured. Each one contains a layers.MultiHeadAttention, a layers.LayerNormalization and a layers.Add
. And we will get started from a simple base class that just contains the component layers
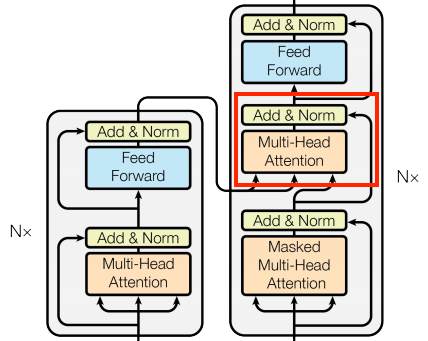
At the literal center of the Transformer is the cross-attention layer. This layer connects the encoder and decoder. This layer is the most straight-forward use of attention in the model, it performs the same task as the attention block
To implement this, we pass the target sequence x as the query and the context sequence as the key/value when calling the mha layer:
This layer is responsible for processing the context sequence, and propagating information along its length:
To implement this layer we just need to pass the target sequence, x, as both the query, and value arguments to the mha layer:
1 2 3 4 5 6 7 8 9
class GlobalSelfAttention(BaseAttention): def call(self, x): attn_output = self.mha( query=x, value=x, key=x) x = self.add([x, attn_output]) x = self.layernorm(x) return x
1 2 3 4 5 6 7 8 9 10 11
# test out the layer sample_gsa = GlobalSelfAttention(num_heads=2, key_dim=512)
This layer does a similar job as the global self-attention layer, for the output sequence:
To build a causal self-attention layer, we need to use an appropriate mask when computing the attention scores and summing the attention values. And we can solve this pass use_causal_mask = True to the MultiHeadAttention layer
1 2 3 4 5 6 7 8 9 10
class CausalSelfAttention(BaseAttention): def call(self, x): attn_output = self.mha( query=x, value=x, key=x, use_causal_mask = True) x = self.add([x, attn_output]) x = self.layernorm(x) return x
1 2 3 4 5 6 7 8 9 10 11
# test out the layer sample_csa = CausalSelfAttention(num_heads=2, key_dim=512)
The transformer also includes this point-wise feed-forward network in both the encoder and decoder:
The network consists of two linear layers (tf.keras.layers.Dense) with a ReLU activation in-between, and a dropout layer. As with the attention layers the code here also includes the residual connection and normalization:
Now we need to put Encoder and Decoder together and add a final linear (Dense) layer which converts the resulting vector at each location into output token probabilities to finish the transformer model to be created.
Create the Transformer by extending tf.keras.Model:
# As the output language is English, initialize the output with the # English `[START]` token. start_end = self.tokenizers.en.tokenize([''])[0] start = start_end[0][tf.newaxis] end = start_end[1][tf.newaxis]
# `tf.TensorArray` is required here (instead of a Python list), so that the # dynamic-loop can be traced by `tf.function`. output_array = tf.TensorArray(dtype=tf.int64, size=0, dynamic_size=True) output_array = output_array.write(0, start)
for i in tf.range(max_length): output = tf.transpose(output_array.stack()) predictions = self.transformer([encoder_input, output], training=False)
# Select the last token from the `seq_len` dimension. predictions = predictions[:, -1:, :] # Shape `(batch_size, 1, vocab_size)`.
predicted_id = tf.argmax(predictions, axis=-1)
# Concatenate the `predicted_id` to the output which is given to the # decoder as its input. output_array = output_array.write(i+1, predicted_id[0])
if predicted_id == end: break
output = tf.transpose(output_array.stack()) # The output shape is `(1, tokens)`. text = tokenizers.en.detokenize(output)[0] # Shape: `()`.
tokens = tokenizers.en.lookup(output)[0]
# `tf.function` prevents us from using the attention_weights that were # calculated on the last iteration of the loop. # So, recalculate them outside the loop. self.transformer([encoder_input, output[:,:-1]], training=False) attention_weights = self.transformer.decoder.last_attn_scores
return text, tokens, attention_weights
Create an instance of this Translator class, and try it out a few times:
#result """ Input: : este é um problema que temos que resolver. Prediction : this is a problem we have to solve . Ground truth : this is a problem we have to solve . """
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# example two sentence = 'os meus vizinhos ouviram sobre esta ideia.' ground_truth = 'and my neighboring homes heard about this idea .'
#result """ Input: : os meus vizinhos ouviram sobre esta ideia . Prediction : and my neighboring homes heard about this idea . Ground truth : and my neighboring homes heard about this idea . """
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# example three sentence = 'vou então muito rapidamente partilhar convosco algumas histórias de algumas coisas mágicas que aconteceram.' ground_truth = "so i'll just share with you some stories very quickly of some magical things that have happened."
#result """ Input: : vou então muito rapidamente partilhar convosco algumas histórias de algumas coisas mágicas que aconteceram . Prediction : so i'll just share with you some stories very quickly of some magical things that have happened . Ground truth : so i'll just share with you some stories very quickly of some magical things that have happened . """
Export the model
Create a class called ExportTranslator by subclassing the tf.Module subclass with a tf.function on the __call__ method:
1 2 3 4 5 6 7 8 9 10 11
class ExportTranslator(tf.Module): def __init__(self, translator): self.translator = translator
translator = ExportTranslator(translator) tf.saved_model.save(translator, export_dir='translator') reloaded = tf.saved_model.load('translator') print(reloaded(tf.constant('este é o primeiro livro que eu fiz.')).numpy().decode("utf-8")) # result: this is the first book I made.
• Enviroment and Dependencies set up • Data Handling (Datasets, Tokenizer, Data Pipeline) • Define the components (encoder,decoder, attention layers and etc) • Train the Model • Run the inference • Export the model