CNNs for Text Classification
Introduction
This article will discuss how to use convolutional neural networks to identify general patterns in text and perform text classification.
Firstly, how do we represent text and prepare it as input for neural networks? Let’s focus on the case of classifying movie reviews, although the same techniques can be applied to articles, tweets, search queries, and more. For movie reviews, we have hundreds of written comments, each consisting of long, opinionated sentences that vary in length.
Neural networks can only learn to find patterns in numerical data. Therefore, before we feed the reviews into the neural network, we must convert each word into a number. This process is commonly referred to as word encoding or tokenization. A typical encoding process works as follows:
For all text data (in this case, movie reviews), we record each unique word that appears in the dataset and list them as the model’s vocabulary.
We assign a unique integer, called a token, to each word in the vocabulary. Typically, these tokens are assigned based on the frequency of the words in the dataset. Thus, the most frequently occurring word across the dataset will have an associated token: 0. For example, if the most common word is “the,” its associated token value would be 0. The next most common word would be assigned the token 1, and this process continues.
In code, this word-token association is represented in a dictionary, which maps each unique word to its token integer value.
{'the': 0, 'of': 1, 'so': 2, 'then': 3, 'you': 4, … }
- Finally, once these tokens are assigned to individual words, we can tokenize the entire corpus.
For any document in the dataset, such as a single movie review, we treat it as a list of words in a sequence. We then use the token dictionary to convert this list of words into a list of integer values.

It is worth noting that these token values don’t carry much traditional meaning. In other words, we generally consider that the value 1 is closer to 2 than to 1000. As another example, we might view the value 10 as an average of 2 and 18. However, a word with a token of 1 is not necessarily more similar to a word with a token of 2 than to one with a token of 1000. The typical concept of numerical distance doesn’t provide us with any information about the relationships between individual words.
Therefore, we must take another encoding step; ideally, we want to either eliminate the numerical order of these tokens or represent the relationships between words.
One-Hot Encoding
A common encoding step is to perform one-hot encoding for each token, representing each word as a vector with as many values as there are words in the vocabulary. That is, each column in the vector represents a possible word in the vocabulary. All positions in the vector are filled with 0s except for the index corresponding to the token value of the word (for example, the index for the would be 0).
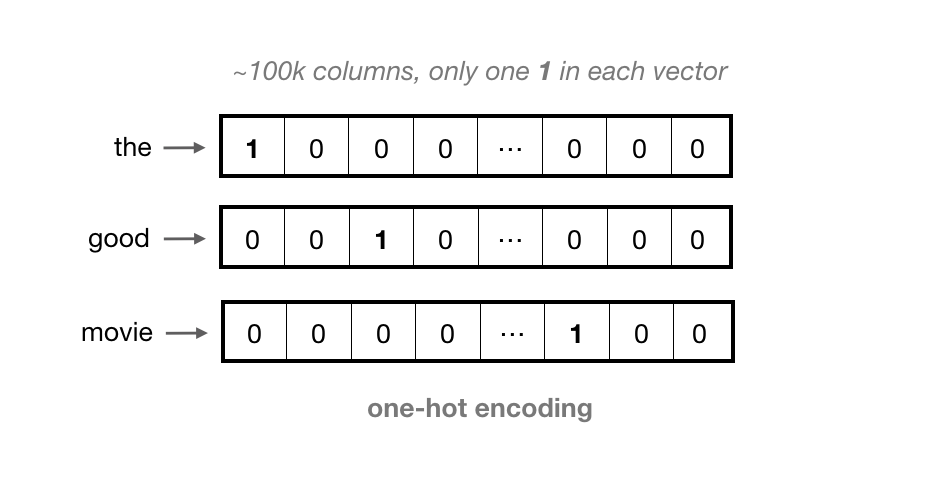
For larger vocabularies, these vectors can become quite long and sparse, containing 0s in all positions except one. This is considered a very sparse representation.
Word2Vec Word Embeddings
Often, we desire a more dense representation. One such representation is learned word vectors, known as embeddings. Word embeddings are fixed-length vectors, typically around 100 dimensions, with each vector containing approximately 100 values that represent a word. The values in each column represent features of a word rather than any specific word.
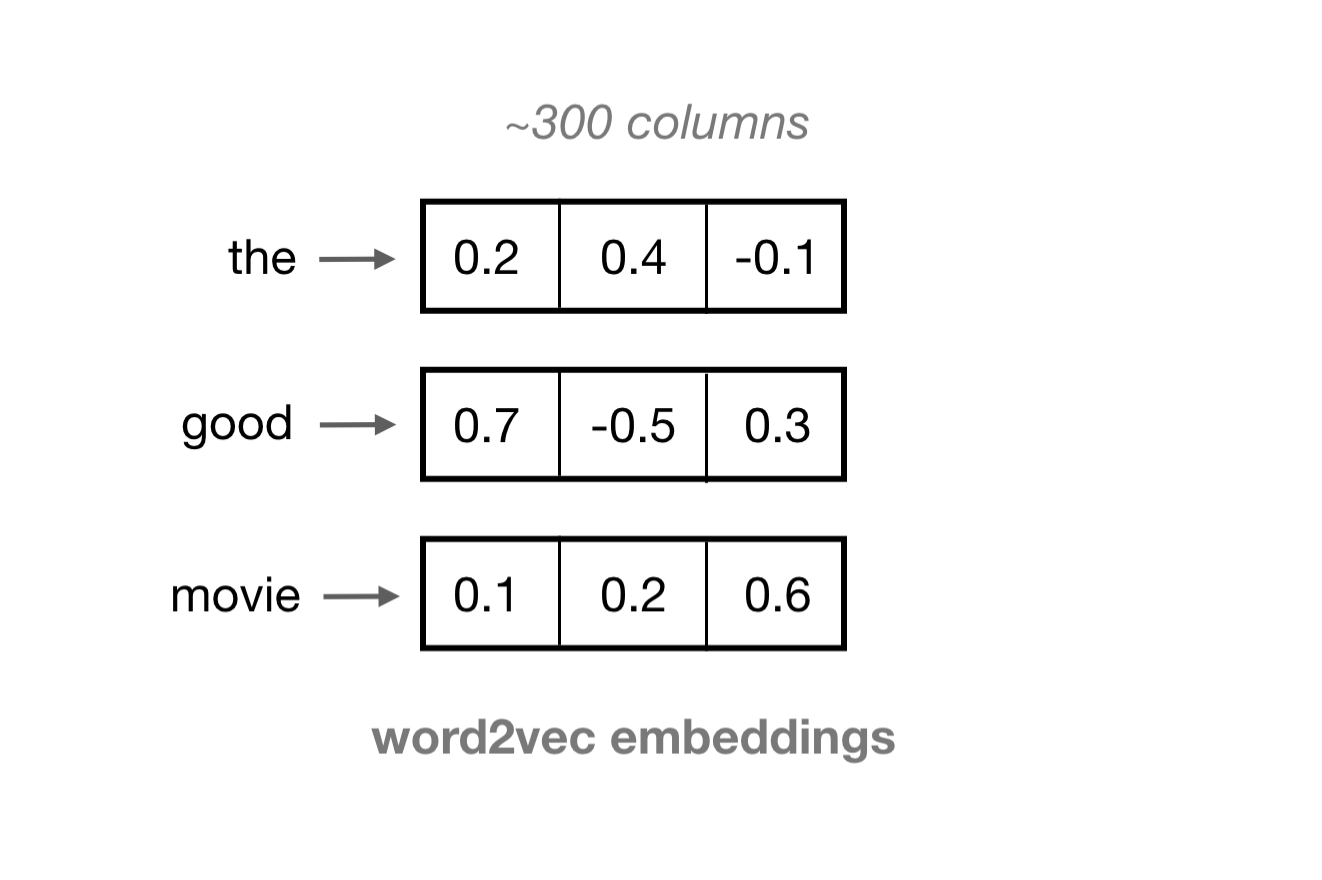
These embeddings are formed through training a single-layer neural network (Word2Vec model) in an unsupervised manner on the input words and some surrounding words in sentences.

Words that appear in similar contexts (and have similar surrounding words), such as coffee, tea, and water, tend to have similar vectors; the vectors point in roughly the same direction. Thus, similar words can be found by calculating the cosine similarity between word vectors. And there are useful resources available for references, including this illustrative code example.
These word embeddings possess some very favorable properties:
- The embeddings are dense vector representations of words.
- Words with similar contexts often have embeddings that point in the same direction.
- These word embeddings can serve as inputs to recurrent neural networks or convolutional neural networks.
Convolutional Kernel
The convolutional layer aims to detect spatial patterns in images by sliding a small kernel window across the image. These windows are typically small, with sizes like 3x3 pixels, and each kernel unit has an associated weight. As the kernel slides pixel-by-pixel over the image, the kernel weights are multiplied by the pixel values in the underlying image, and the sum of all these products yields an output, the filtered pixel value.
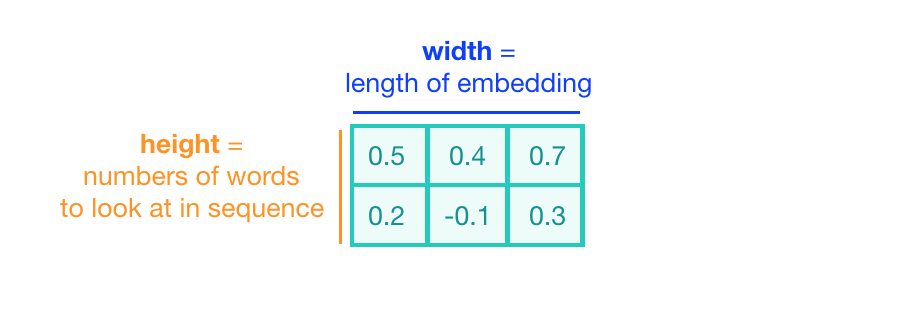
In the case of text classification, the convolutional kernel still acts as a sliding window, but its job is to examine multiple word embeddings rather than small areas of pixels in an image. Depending on the task, the size of the convolutional kernel must also change. To look at a sequence of word embeddings, we need a window that examines multiple word embeddings in the sequence. The kernel will no longer be square but will be a wide rectangle of sizes like 3x300 or 5x300 (assuming the embedding length is 300).
The height of the kernel corresponds to the number of embeddings it sees at once, similar to representing n-grams in word models.
The width of the kernel should span the entire length of the word embeddings.
Convolution on Word Sequences
Let’s take a look at an example of filtered word embeddings for a pair of (2-grams). Below, we have a toy example showing each word encoded as an embedding with 3 values; usually, this would contain more values, but this is for visualization purposes.
To observe the two words in this example sequence, we can use a 2x3 convolutional kernel. The kernel weights are placed on top of the two word embeddings; in this case, the downward direction represents time, so within this short sequence, the word “movie” follows closely after the word “good.” The kernel weights and embedding values are multiplied together, and then summed to obtain a single output value of 0.54.
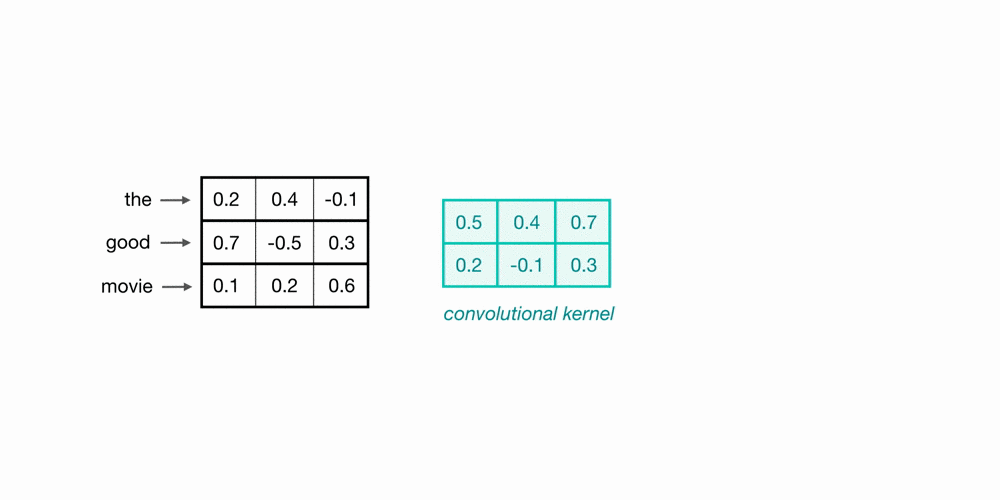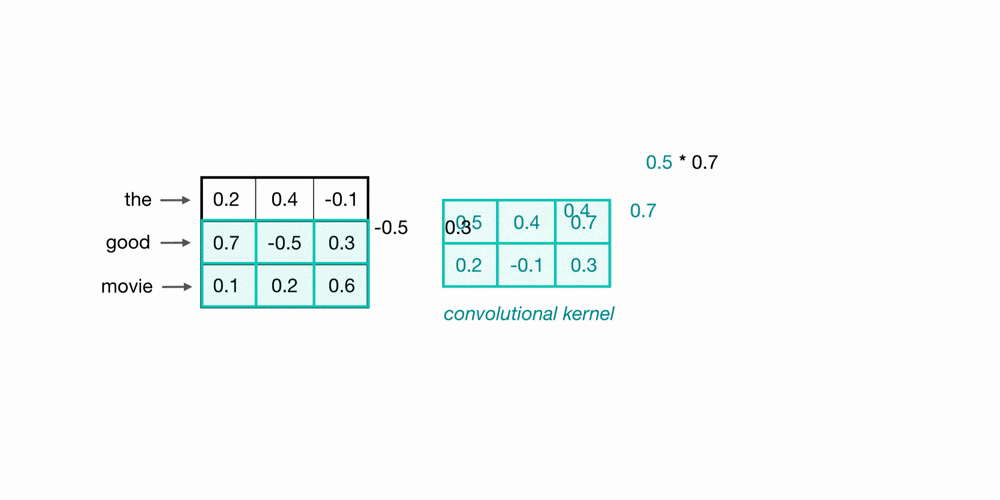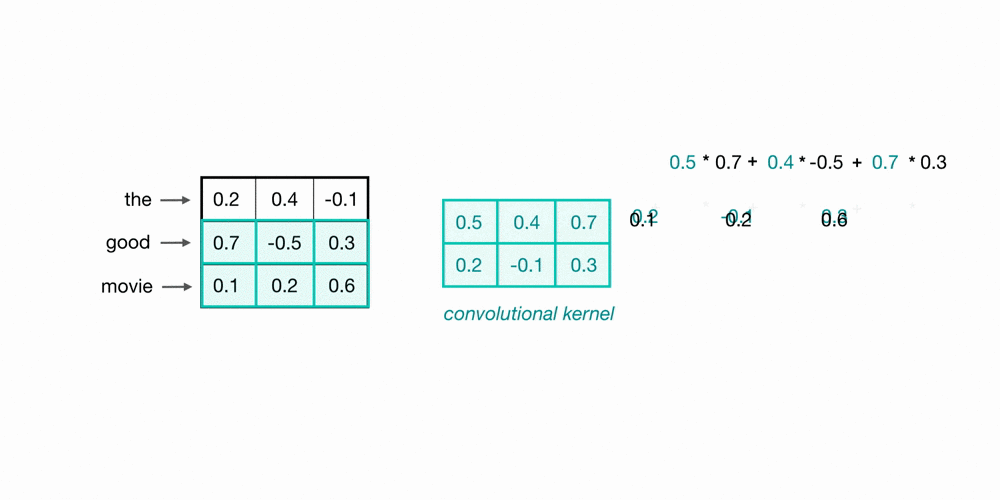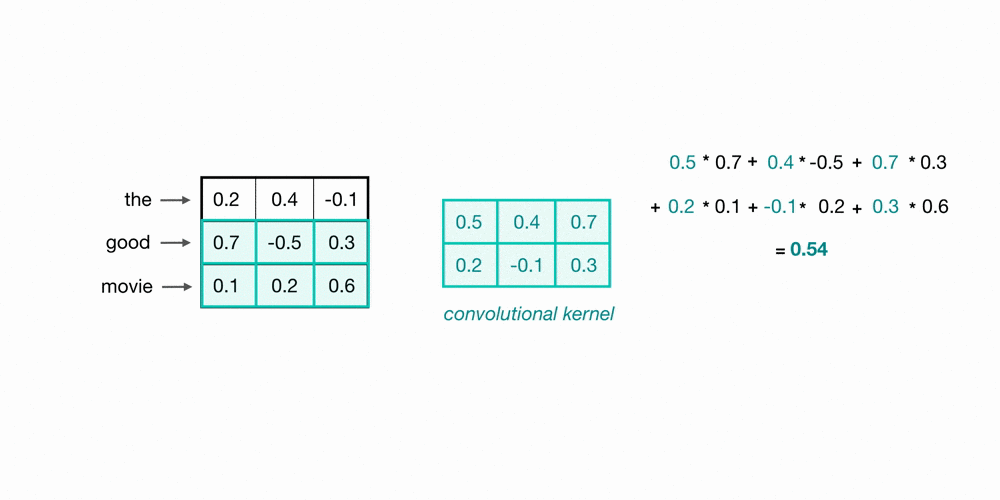
The convolutional neural network will contain many such kernels, and during network training, these kernel weights are learned. Each kernel is designed to view a word along with its surrounding words in a sequential window and produce a value that captures information about that phrase. Thus, the convolution operation can be seen as window-based feature extraction, where features are patterns in groups of sequential words indicating sentiment, grammatical function, etc.
It’s also worth noting that the input channel count for this convolutional layer (typically 1 for grayscale images and 3 for RGB images) in this example will be 1 since a single input text source will be encoded as a list of word embeddings.
Recognizing General Patterns
This convolution operation has another beneficial characteristic. Recall that similar words will have similar embeddings, and convolution operations are merely linear operations on these vectors. Therefore, when the convolutional kernel is applied to different sets of similar words, it will yield similar output values.
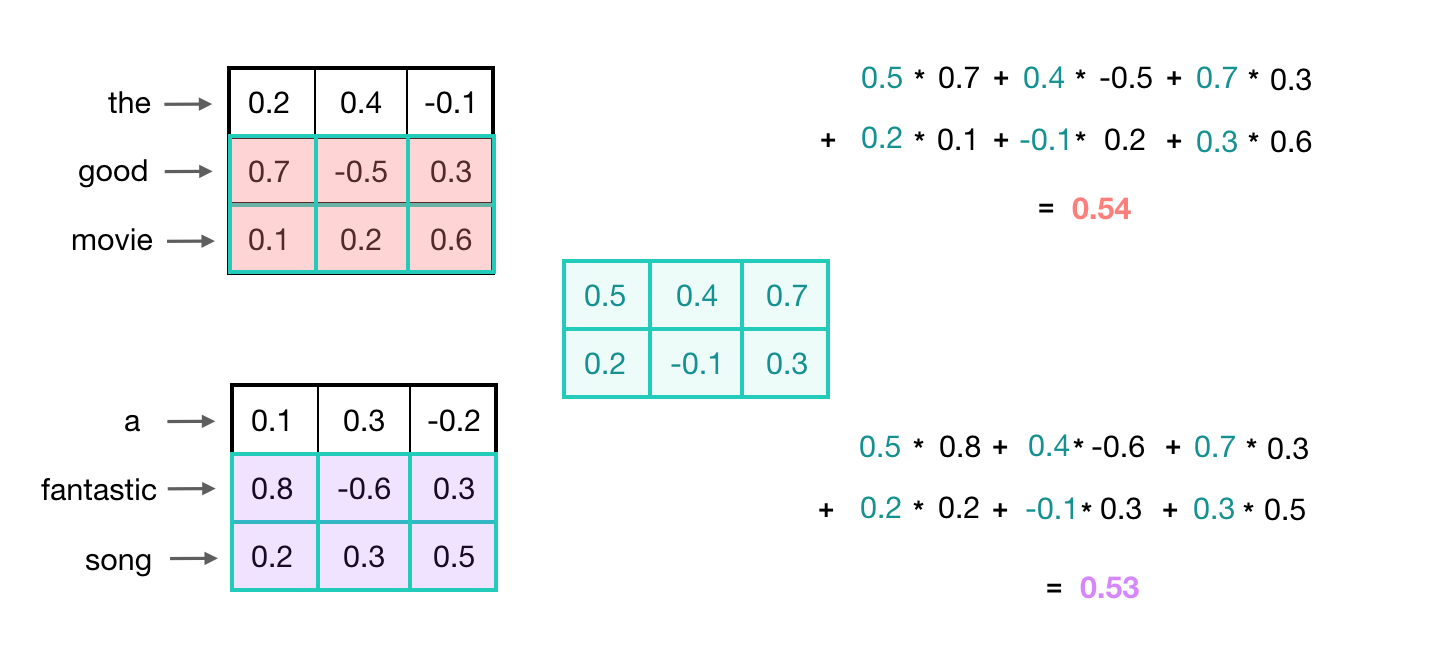
In the example below, we can see that the input 2-grams “good movie” and “great song” produce approximately the same convolution output values because the word embeddings for these pairs are also very similar.
In this case, the convolutional kernel has learned to capture more general features; not just a good movie or a great song, but overall something positive. Recognizing these high-level features is particularly useful in text classification tasks, as they often rely on general groupings. For instance, in sentiment analysis, the model benefits from being able to represent phrases that are negative, neutral, and positive. The model can use these general features to classify the entire text.
1D Convolution
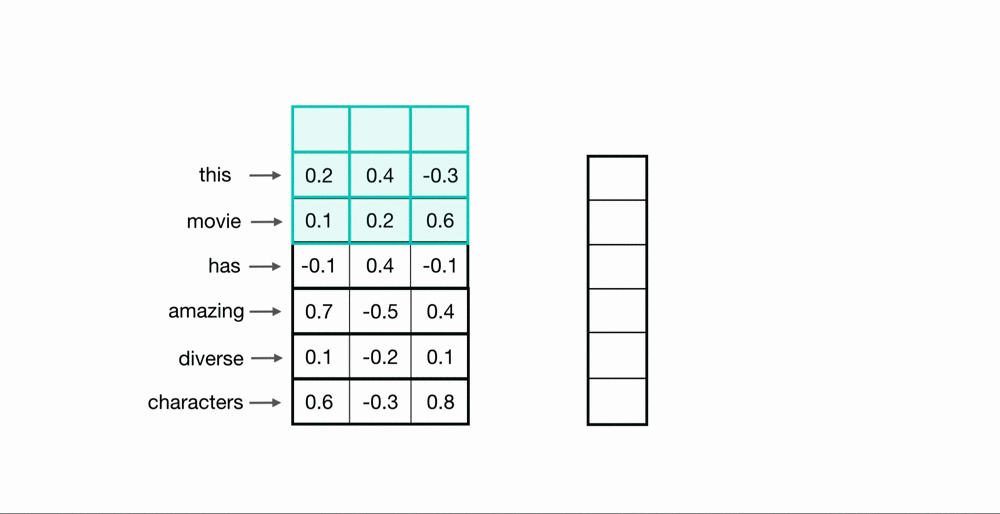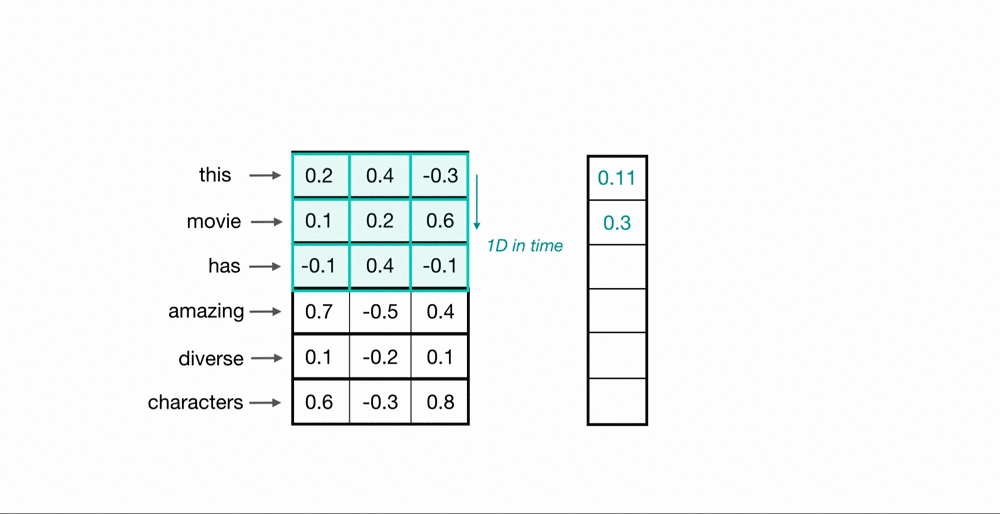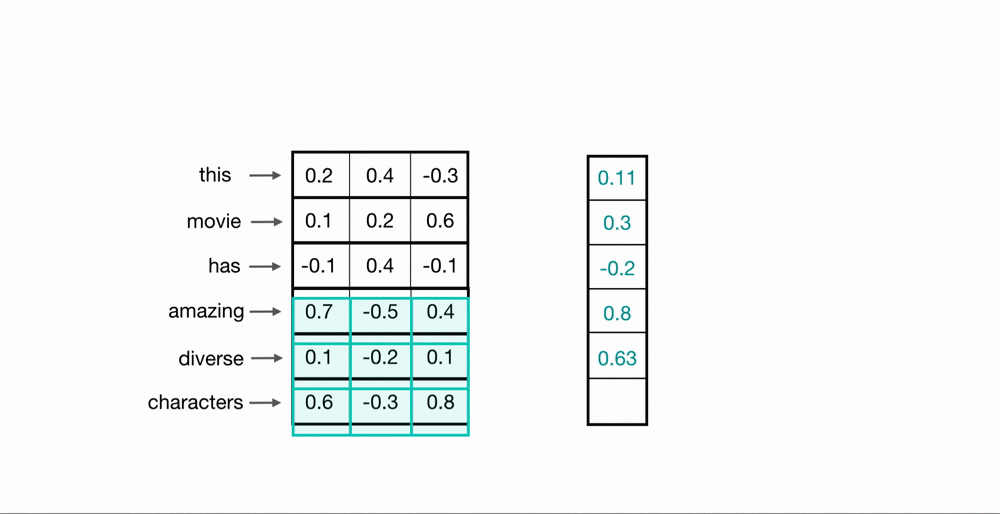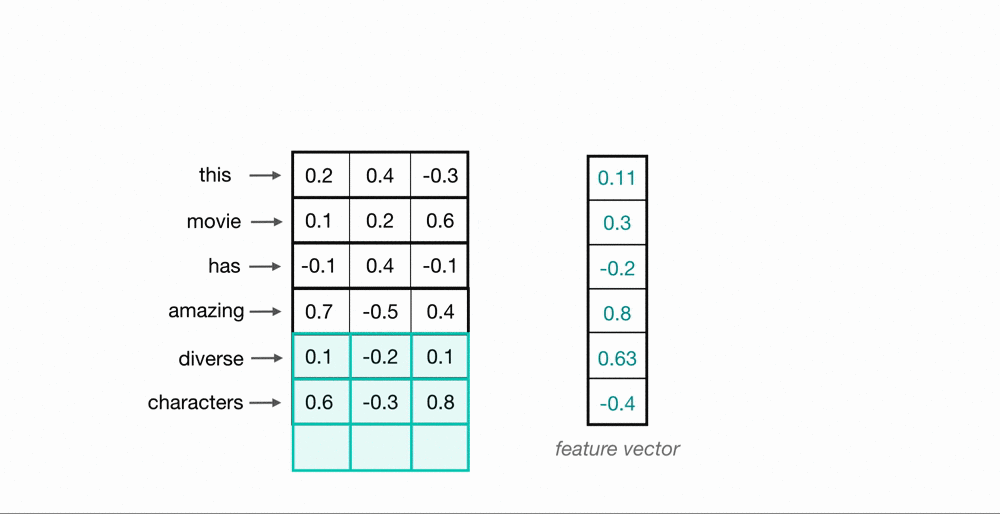
To process entire sequences of words, these kernels will slide down the list of word embeddings sequentially. This is referred to as 1D convolution because the kernels only move in one dimension: time. A single kernel moves down the input embedding list one by one, looking at the first word embedding (along with a small window of the next word embeddings), then the next, and so on. The final output will be a feature vector containing as many values as the input embeddings, so the size of the input sequence is indeed important. I say “about” because sometimes the convolutional kernels won’t perfectly cover the word embeddings, hence padding may need to be included to account for the kernel’s height. The previous article describes the relationship between padding and kernel size in more detail. Below, we can see what the output of 1D convolution might look like when applied to a short sequence of word embeddings.
Multiple Kernels
Just as in a typical convolutional neural network, a single convolutional kernel is insufficient to detect all the different types of features useful for classification tasks. To build a network capable of learning various relationships between words, we need many different filters of varying heights. In the paper Convolutional Neural Networks for Sentence Classification (Yoon Kim, 2014), they used a total of 300 kernels; 100 kernels for each height: 3, 4, and 5. These heights effectively capture patterns in sequences of 3, 4, and 5 continuous words. They chose 5 words as a cutoff because words that are further apart generally have lower relevance or usefulness for identifying patterns within a phrase. For example, if I say this apple is red, and a banana is yellow then words like this apple and red that are close together are more relevant than words like apple and yellow that are farther apart. Therefore, as a short convolutional kernel slides over the word embeddings one at a time, it is designed to capture local features or characteristics within nearby continuous word windows. The stacked output feature vectors produced by several convolution operations are referred to as the convolutional layer.
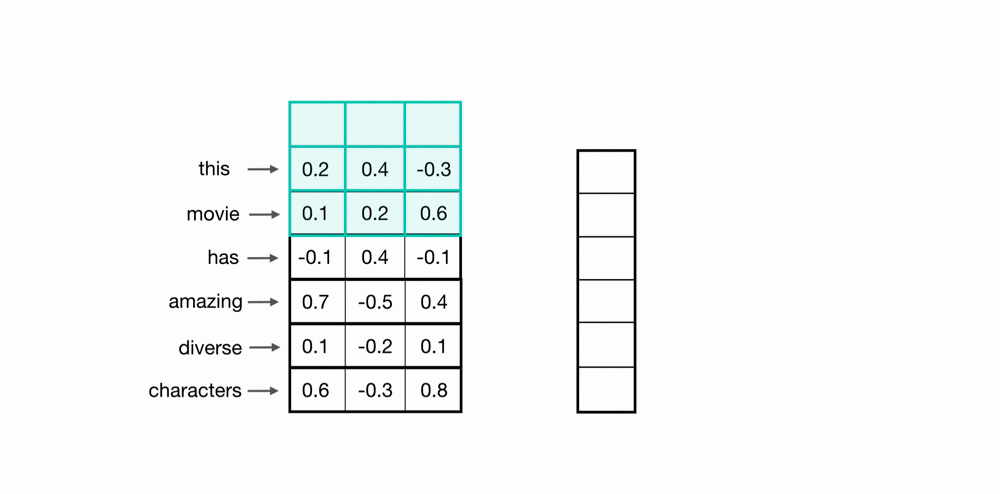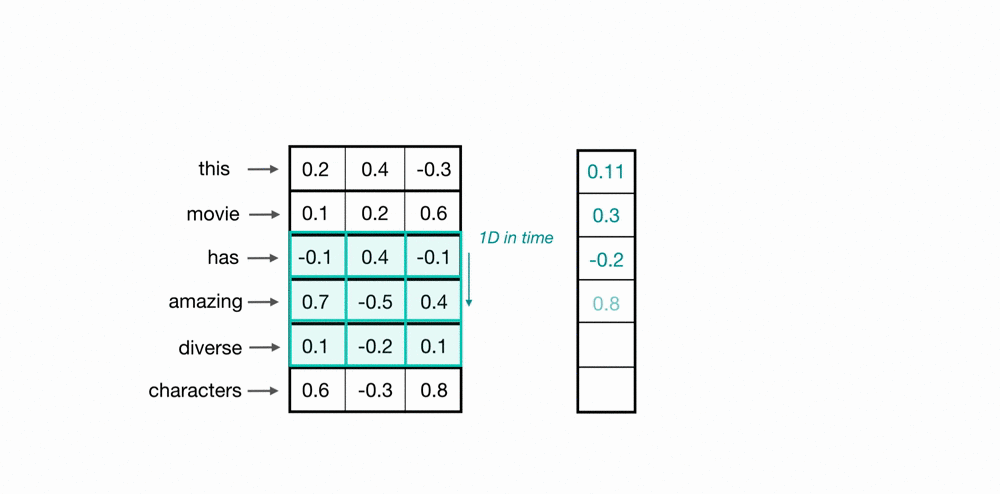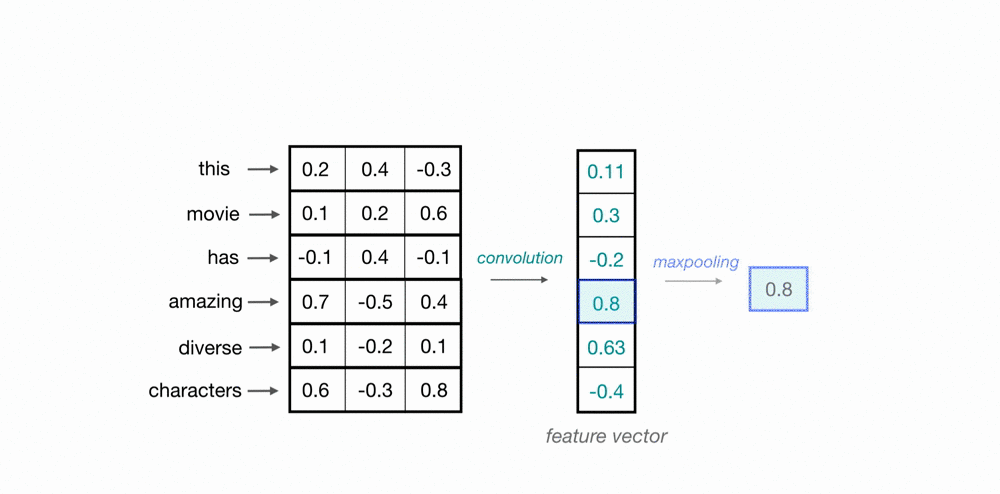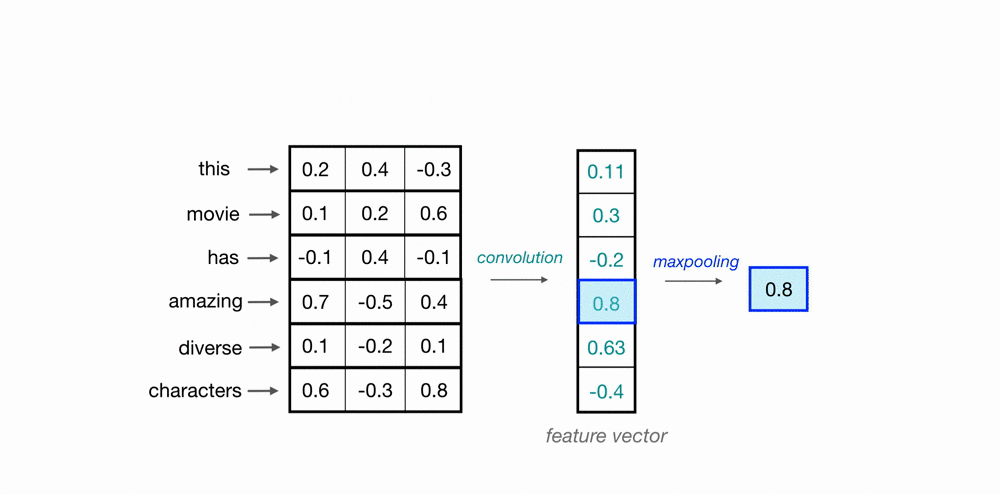
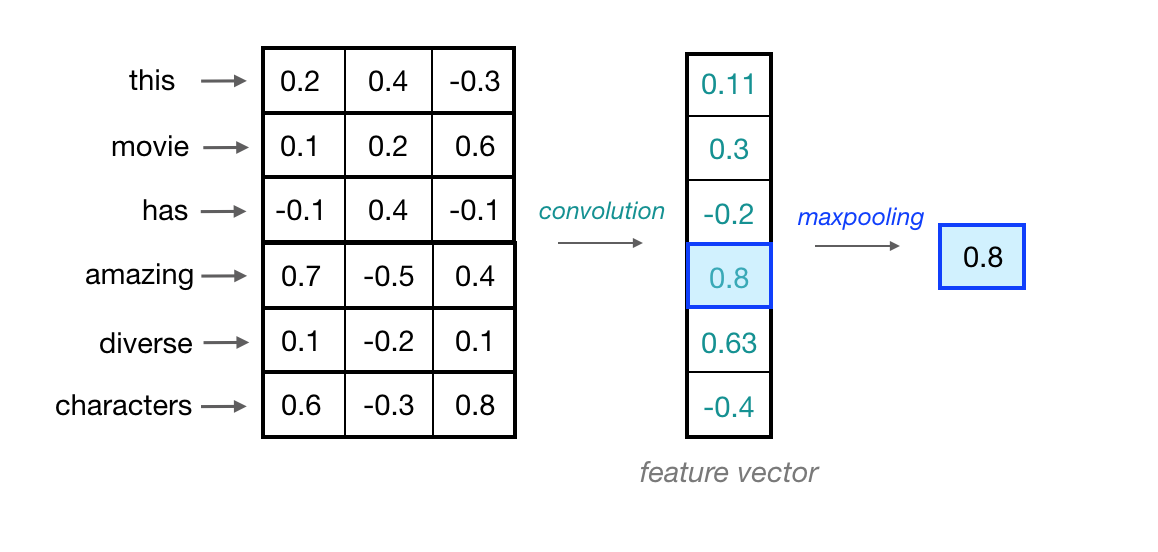
Maxpooling Over Time
Now that we understand how the convolution operation generates feature vectors that can represent local features within a sequence of word embeddings, one consideration is what these feature vectors will look like when applied to important phrases in the text source. If we are trying to classify movie reviews and see the phrase great plot the position it appears in the review doesn’t matter; what matters is that it appears in the review. This serves as a strong indicator that this is a positive review, regardless of its position in the source text.
To indicate the presence of these high-level features, we need a method to recognize them in the vector, regardless of their location in the larger input sequence. One way to identify significant features is to discard less relevant positional information, regardless of where they are in the sequence. For this, we can use the maxpooling operation, which forces the network to retain only the maximum value from the feature vector, which should be the most useful local feature.
Since this operation looks at a series of local feature values, it is commonly referred to as max pooling over time.
By processing the maximum value produced from each convolutional feature vector, these maximums will be concatenated and passed to the final fully connected layer, which can generate as many class scores as needed for the text classification task.
Summarization
In the text classification process using Convolutional Neural Networks (CNNs), the complete network begins by receiving a batch of texts (for example movie reviews) as input. Initially, these reviews are transformed into word embeddings through a pre-trained embedding layer, which captures semantic similarities between words in a continuous vector space. Following this, the sequences of word embeddings are processed through multiple convolutional layers with varying kernel heights of 3, 4, and 5 or even higher
Each convolutional layer applies filters that slide over the embedded sequences, detecting local patterns and features within the text. After the convolution operations, a ReLU activation function is applied to introduce non-linearity, enabling the model to learn complex representations. Subsequently, a max pooling operation is performed, where the maximum values from the feature maps are extracted, effectively summarizing the most salient features detected by each convolutional layer.
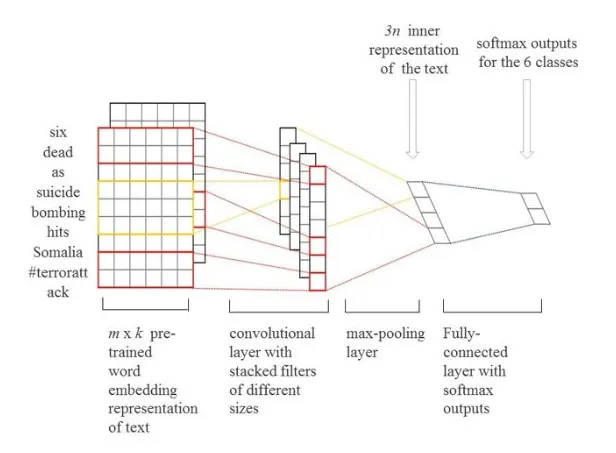
Finally, the maximum values from the convolutional layers are concatenated to form a comprehensive feature vector. This vector is then fed into a fully connected classification layer, which outputs class scores corresponding to the category of the texts. Through this systematic approach, CNNs leverage their ability to capture spatial hierarchies in data, making them particularly effective for text classification tasks.
References
CNNs for Text Classification
http://paddyzz.github.io/blogs/CNNs_For_Text_Classification/